



文心一格-文生圖
智能用文字創作圖片,可編輯圖片

用一分鐘的語音,就能讓AI模仿我的聲音,一鍵翻唱任意歌曲,你敢信?
上周的小和尚語錄制作教程,很多友友都表示對AI克隆聲音非常感興趣,還發來了一段大合唱視頻:
用AI克隆聲音,仿佛真的是四郎和諸葛亮在線合唱,竟然毫無違和感,看著挺有意思的,難怪在互聯網上一直熱度不減。
很多人好奇,這樣的翻唱視頻是怎么制作的?
其實只需要AI克隆聲音翻唱+對口型。GitHub上也有了比較成熟的SVC(歌聲轉換)技術,但本地部署對電腦配置要求高,還需要大量的語音素材去訓練,我覺得很麻煩。
今天給大家分享兩個超級簡單的工具,上傳一分鐘的原聲素材,點點點就行了,0基礎小白,也能快速生成翻唱作品。
如果你電腦配置不高,直接用網頁版,云端有大量的語音模型可以用于翻唱,不用花時間訓練,效果還杠杠好,重點是完全免費!用起來簡直不要太香。
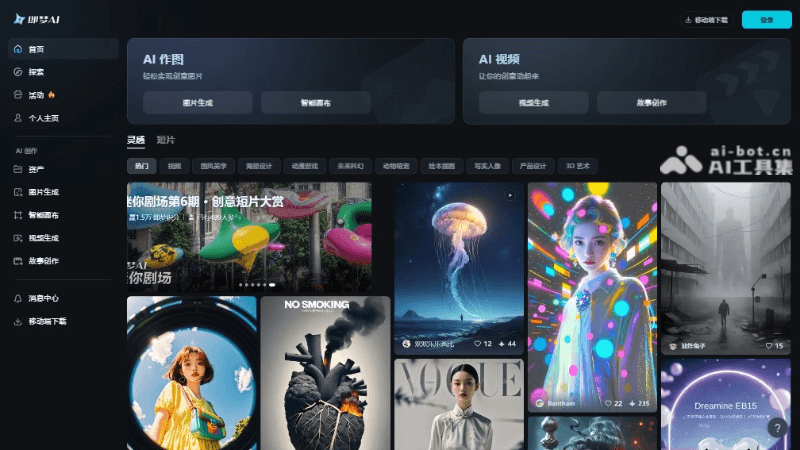
Weights三步生成翻唱
選擇模型、上傳音頻、微調設置
進入Weights官網(建議打開網頁翻譯功能),第一個板塊就是超級多訓練好的語音模型,直接免費用!點擊查看全部,我們可以看到從虛擬角色到明星大佬,像海綿寶寶、邁克?杰克遜、霉霉、初音未來…挑起來真的是眼花繚亂。
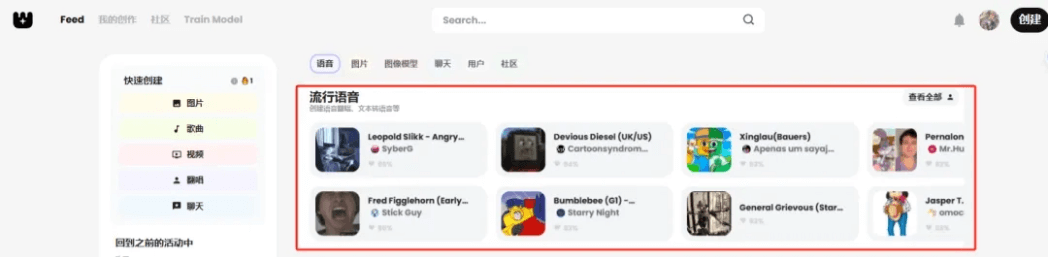
嘗試搜了一下我的偶像,沒想到他的語音模型居然有好幾個,我選擇了排名最靠前的這一個,點擊右上角的創建,新建一個翻唱任務。

點擊下一步。
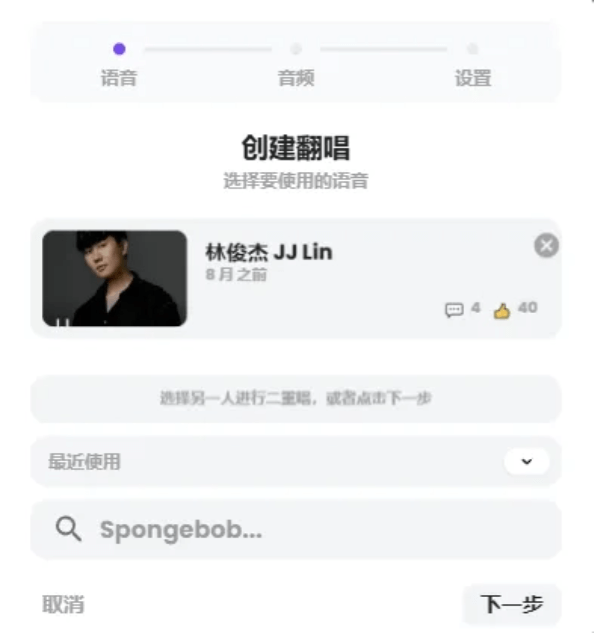
翻唱的音頻,我們可以直接復制YouTube鏈接上傳,也可以直接將歌曲文件拖放進來。
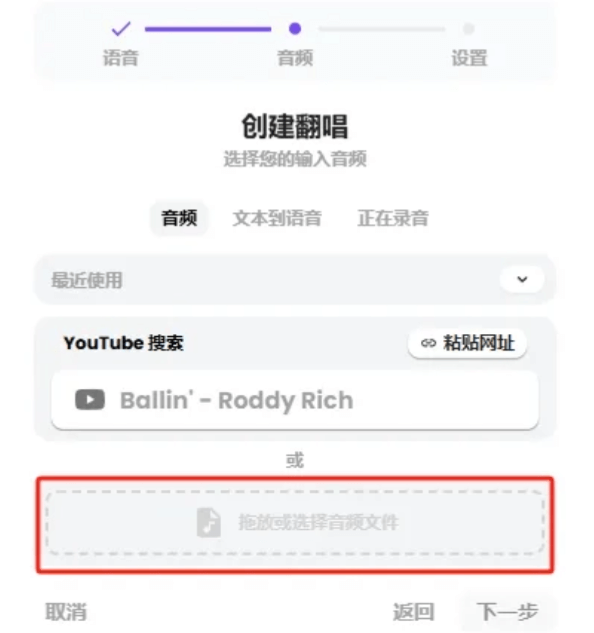
它不僅支持歌聲翻唱,還可以輸入文本轉語音,或者直接用麥克風輸入語音翻唱,這也太全面了~
和聲、混響對翻唱效果都會有一些影響,所以這里我選擇了一段單人清唱的音頻。我們一起來聽一下:
(土坡上的狗尾巴草)
上傳音頻后,點下一步。
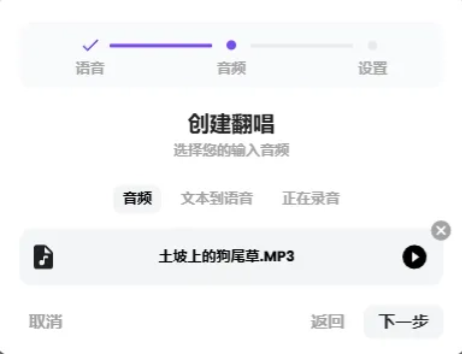
我上傳的是僅人聲的清唱,勾選上預混。音調方面,如果男聲模型翻唱女聲歌曲,可以適當調低一些音調,反之則調高;這里我們用默認即可。
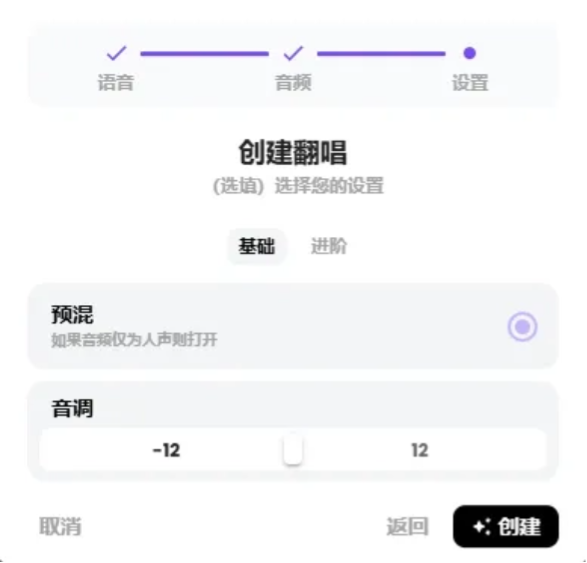
進階的選項可以做一些更細致的調整,建議先用默認,如果生成的效果不滿意,再進行微調。點擊右下角的創建。

進入左上角我的創作,就可以看到翻唱歌曲正在排隊生成啦,一般只需要等待幾分鐘。

等列表里跳出成功的提示后,可以試聽和下載。

下載界面里的音頻,依次是:翻唱后的人聲+伴奏(如有)、翻唱后的干聲、原始音頻、原始音頻中的干聲、原始音頻中的伴奏。

我們一起來聽一下,翻唱后的音頻。
聲音很有特色,演唱的連貫自然,很有節奏感,轉音、重音、高音表現都還不錯。
而這整套操作下來,幾分鐘就完事了,可以說是有手就會。
同樣的方法,我用周杰倫和鄧紫棋的模型,也翻唱了一遍,一起來聽一下。
(??周杰倫-土坡上的狗尾巴草)
我們將音頻按照合唱的節奏切成幾段,每一小段搭配一張Q版的人像,上傳到即夢,生成對口型視頻。

用圖片對口型,生成效果一定要選擇生動,不然標準的只動嘴不動頭,看起來會很僵硬。
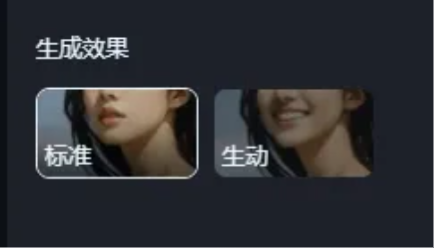
生成好的片段,用剪映組合,(如果有伴奏的話,加上伴奏),一個AI合唱視頻就做完啦,我們來看看效果。
如果我想要自己創建語音模型來做翻唱,要怎么操作呢?
Replay一鍵分離人聲
訓練自己的語音模型
我們一起嘗試做一個懶羊羊的聲音模型和翻唱吧!
首先,需要進去Replay的官網,下載最新的軟件。
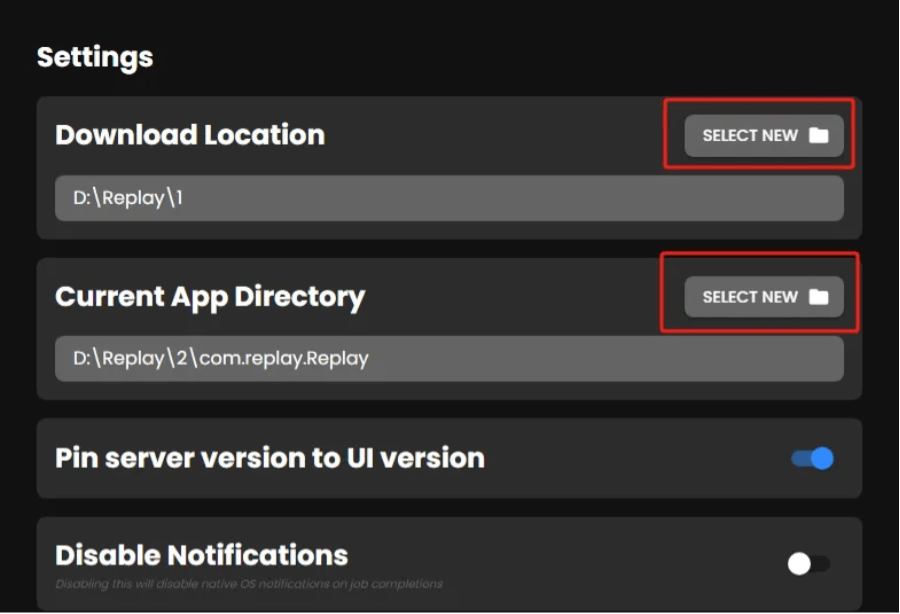
要注意,安裝軟件之后,首次打開會彈出兩個提示框,先別急著去點!!!先去左上角App-Show Settings修改一下文件保存位置。

第一個文件夾是導出音頻的位置。第二個文件夾是一些應用數據,語音模型、生成音頻的數據等等都會保存在這里。總之,別放C盤,其它隨意~
我們先從B站扒一段懶羊羊唱歌的視頻,用剪映做一下前置處理,只保留懶羊羊聲音的片段,導出為mp3/wav格式。將音頻上傳(如圖所示位置)。

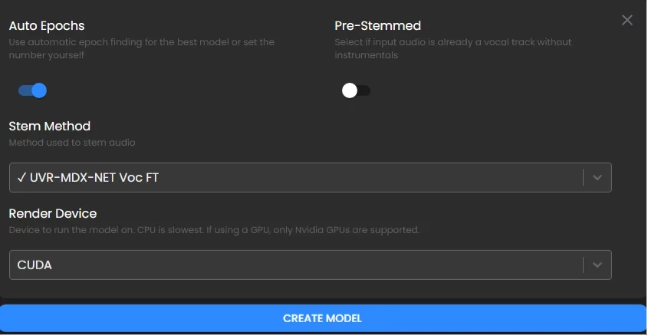
選擇僅干聲。

渲染設備這里,電腦有核顯就選CUDA,會生成的稍微快一些,沒有核顯需要調成CPU。其它設置保持默認即可,點擊生成。

生成的音頻會出現在左側列表中,單擊一下就可以看到分離出來的干聲和伴奏聲,可以分別試聽和下載。

我們下載分離出的干聲,將文件上傳到訓練模型的版塊。這里可以上傳多個文件,要盡可能多地覆蓋各種聲線,翻唱的效果就會更理想。
沒有經過高音訓練的語音模型,翻唱高音會容易失真甚至破音哈哈哈!

下面的設置,除了渲染設備這里,其它保持默認即可,點擊創建模型。這個過程比較久,大概需要幾個小時。
訓練好的模型會在這里顯示。

我們試一下用剛生成的懶羊羊模型翻唱,上傳想要翻唱的歌曲。
(??若月亮還沒來-片段)
點擊選擇懶羊羊的語音模型。

下方的設置保持默認就行,和在線翻唱的時候差不多,可以適當調整人聲和樂器的音高,點擊生成。

不到一分鐘,就翻唱好啦。我們分別保存翻唱后的干聲和伴奏。

一起來聽聽看:
下載Weights上的語音模型,解壓后放入應用程序目錄文件夾(軟件開始設置的第二個位置)下的models文件里中,就可以在Replay中直接使用。
做合唱視頻,只需要將同一段音頻用不同的模型分別翻唱,最后用剪映拼接起來就可以啦。是不是非常簡單方便。來聽聽懶羊羊和蠟筆小新的合唱。
只用一分鐘的聲音素材,就能達到不錯的翻唱效果,使用下來,除了生成模型有點慢(是我的缺點…),整體體驗都很不錯。特別是人聲分離這個功能,基本上在其它平臺都是要開會員才能用的,而Replay和Weights,都可以免費、無限次使用,效果還很贊,很難不愛呀。
翻唱音樂如果有和聲、混響之類的,會影響翻唱的效果。如果我們想要做合唱類型的歌曲,可以先分別用單人版翻唱,再去剪映中合成。
用自己的聲音訓練模型,就能讓AI翻唱各種熱門歌曲,再也不用擔心跑調,喊麥、說唱、流行音樂,分分鐘拿捏,那些好聽又難唱的歌,我用另一種方式學會啦。
AI翻唱雖然不能100%復刻聲音和唱功,但已經可以聽出七八分歌手的音色了,讓賽博idol每天為我唱歌,想想還有點小激動呢~
本文轉載自互聯網,如有侵權,聯系郵箱:478266466@qq.com 刪除









